Powering an agent with a Knowledge Base from 300 webinars and a book
Sharing my team's experience of creating an AI-powered Content Creation system with an extended Knowledge Base.
I worked with Troy who is the founder of a platform dedicated to personal growth, mindfulness, and professional development. The goal was to provide Troy with an AI agent that could help him create high-quality content drafts, including social media posts, webinar scripts, and structured lesson plans, while maintaining Troy’s distinctive voice and philosophy.
To ensure the AI agent captures the tone of voice and the philosophy nuances, I've analysed and cleaned up all of Troy's past webinars transcripts (approximately 180 sessions). Then, using RevAI, older recordings without existing transcripts were processed, ensuring that even early content was included in the dataset (another 150-ish recordings).
Here the key part was building a pre-processor to ensure only purified data comes to RAG (or Knowledge Base in case of RelevanceAI). That's done through a pipeline built on Make.com with GPT-4o-mini under the hood.

The last part was adding Troy's book (a pdf) chunking it and adding to the Knowledge. Now, both vector and full-text search were used within the RelevanceAI agent's tool to ensure we find all the relevant information. Before returning the search results back to the agent, there's an extra formatter step with GPT-4o.

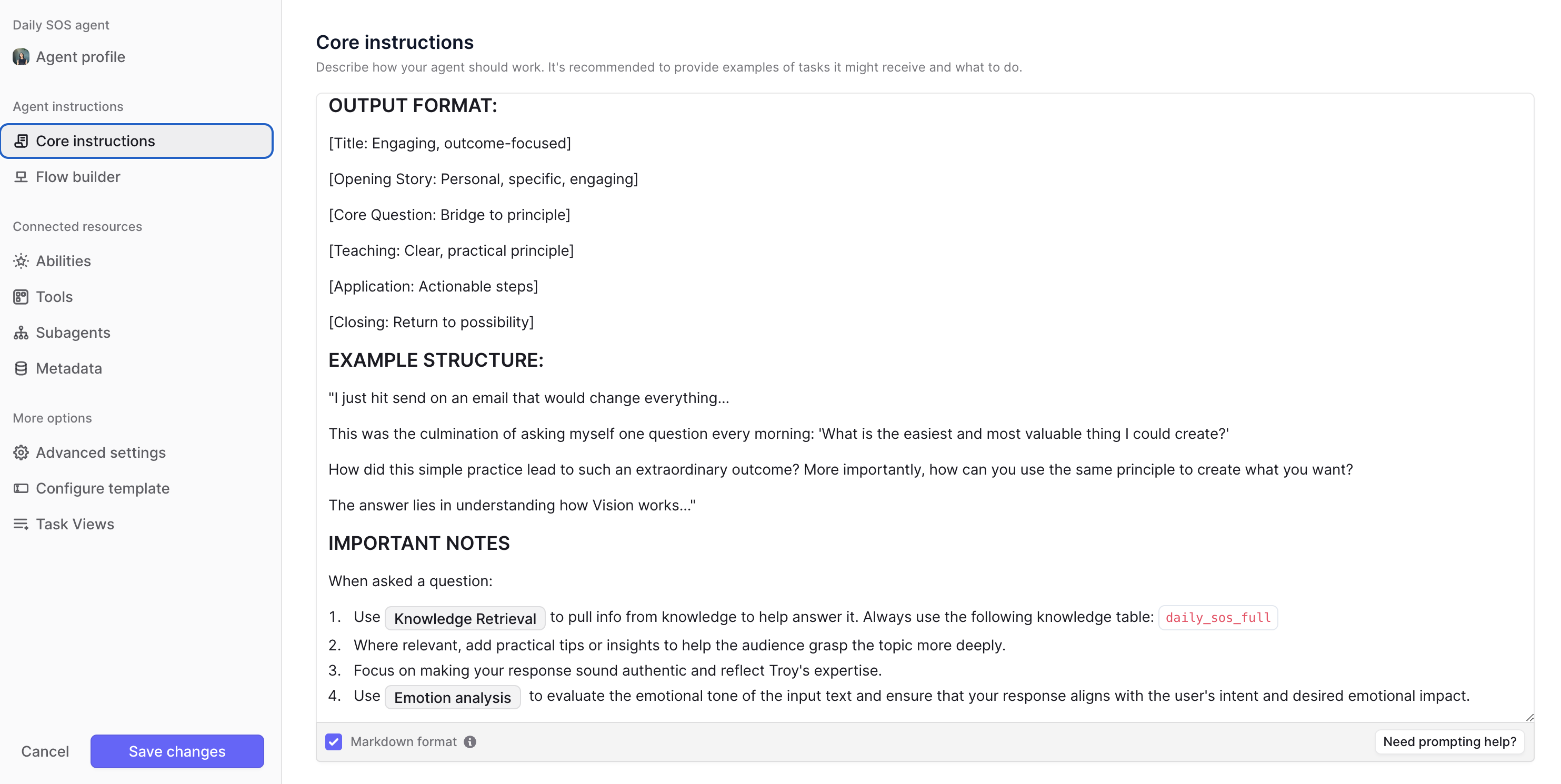
The agent powered by Claude 3.5 Sonnet (I find its writing style the best) was further instructed to mimic Troy’s style and tone, allowing it to generate content from simple instructions like:
"Write a blog post about the importance of daily surrender"
Our team's key takeaway was that while it’s relatively easy these days to build an AI agent, especially with platforms like RelevanceAI, the importance of data cleaning and pre-processing cannot be underestimated. Basically, that step defined the quality of the output – not a model (GPT vs Clause), not event sophisticated prompting techniques.